- A+

从技术的角度分析,个人觉得,3月份AlphaGo要战胜李世石难度是比较大的。为什么呢?请看下文。
一、AlphaGo的两大核心技术
- MCTS(MonteCarloTreeSearch)
MCTS之于围棋就像Alpha-Beta搜索之于象棋,是核心的算法,而比赛时的搜索速度至关重要。就像深蓝当年战胜时,超级计算机的运算速度是制胜的关键因素之一。
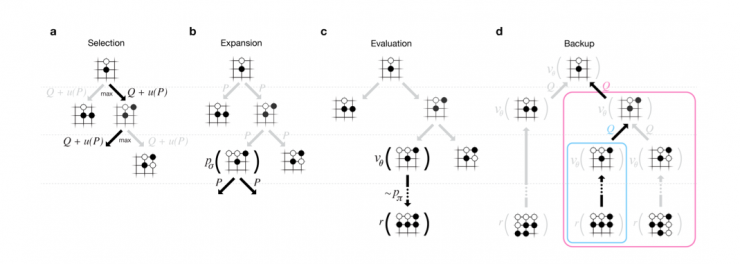
MCTS的4个步骤:Selection,Expansion,Evaluation(rollout)和Backup
MCTS的并行搜索:
(1)LeafParallelisation
最简单的是LeafParallelisation,一个叶子用多个线程进行多次Simulation,完全不改变之前的算法,把原来的一次Simulation的统计量用多次来代替,这样理论上应该准确不少。但这种并行的问题是需要等待最慢的那个结束才能更新统计量;而且搜索的路径数没有增多。
(2)RootParallelisation
多个线程各自搜索各自的UCT树,最后投票
(3)TreeParallelisation
这是真正的并行搜索,用多个线程同时搜索UCT树。当然统计量的更新需要考虑多线程的问题,比如要加锁。
另外一个问题就是多个线程很可能同时走一样的路径(因为大家都选择目前看起来Promising的孩子),一种方法就是临时的修改virtualloss,比如线程1在搜索孩子a,那么就给它的Q(v)减一个很大的数,这样其它线程就不太可能选择它了。当然线程1搜索完了之后要记得改回来。
《ALock-freeMultithreadedMonte-CarloTreeSearchAlgorithm》使用了一种lock-free的算法,这种方法比加锁的方法要快很多,AlphaGo也用了这个方法。
Segal研究了为什么多机的MCTS算法很难,并且实验得出结论使用virtualloss的多线程版本能比较完美的scale到64个线程(当然这是单机一个进程的多线程程序)。AlphaGo的Rollout是用CPU集群来加速的,但是其它的三个步骤是在一台机器完成的,这个就是最大的瓶颈。
- DCNN(DeepConvolutionalNeuralNetwork)
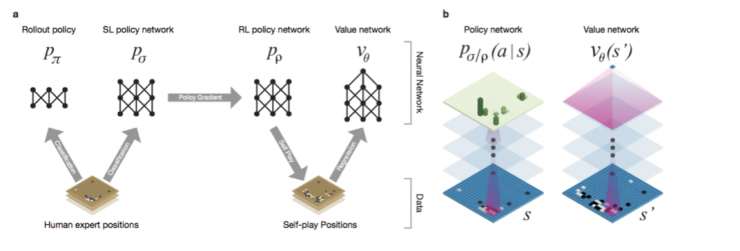
(使用深度神经网络训练的PolicyNetwork和ValueNetwork)
神经网络训练的时间一般很长,即使用GPU,一般也是用天来计算。Google使用GPUCluster来训练,从论文中看,训练时间最长的ValueNetwork也只是用50个GPU训练了一周。
给定一个输入,用卷积神经网络来预测,基本运算是矩阵向量运算和卷积,由于神经网络大量的参数,用CPU来运算也是比较慢的。所以一般也是用GPU来加速,而AlphaGo是用GPU的cluster来加速的。
更多技术细节请参考我的文章《alphaGo对战李世石谁能赢?两万字长文深挖围棋AI技术》
1.论文送审时(2015年11月)AlphaGo的水平
论文里使用EloRating系统的水平:
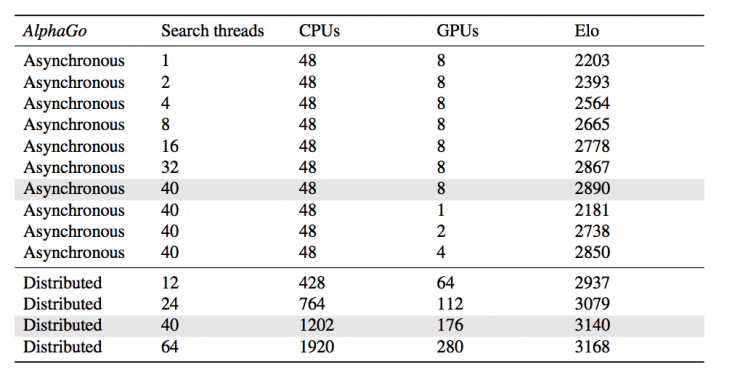
a图是用分布式的AlphaGo,单机版的AlphaGo,CrazyStone等主流围棋软件进行比赛,然后使用的是EloRating的打分。
笔者认为AlphaGo的水平超过了FanHui(2p),因此AlphaGo的水平应该达到了2p。【不过很多人认为目前Fanhui的水平可能到不了2p】
b图说明了PolicyNetworkValueNetwork和Rollout的作用,做了一些实验,去掉一些的情况下棋力的变化,结论当然是三个都很重要。
c图说明了搜索线程数以及分布式搜索对棋力的提升,这些细节我们会在下一节再讨论,包括AlphaGO的架构能不能再scalable到更多机器的集群从而提升棋力。
- AlphaGo的真实棋力
笔者这里根据一些新闻做推测。而且从文章提交Nature审稿到3月份比赛还有一段不短的时间,AlphaGo能不能还有提高也是非常关键。这里我只是推测一下在文章提交Nature时候AlphaGo的棋力。至于AlphaGo棋力能否提高,我们下一节分析实现细节时再讨论(假设整体架构不变,系统能不能通过增加机器来提高棋力)。
网上很多文章试图通过AlphaGo与fanhui的对局来估计AlphaGo的棋力,我本人围棋水平离入门都比较远,所以就不敢发表意见了。我只是搜索了一些相关的资料,主要是在弈城上一个叫DeepMind的账号的对局信息来分析的。
比如这篇《金灿佑分析deepmind棋谱认为99%与谷歌团队相关》。作者认为这个账号就是AlphaGo。如果猜测正确的话,AlphaGo当时的棋力在弈城8d-9d之间,换成我们常用的rankingsystem的话大概也就是6d-7d(业余6段到7段)的水平,如果发挥得好,最多也许能到1p的水平,战胜fanhui也有一定合理性(很多人认为fanhui目前实际水平可能已经没有2p了,那算1p的话也差不多)
知乎的这个话题AlphaGo也有很多讨论,可供参考。
二、AlphaGo到比赛前可能的提升
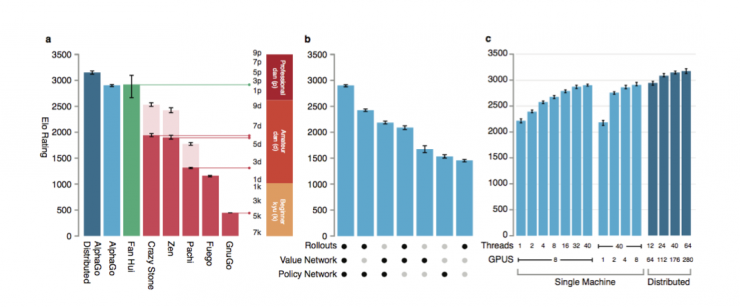
不同分布式版本的水平比较,使用的是Elorating标准
最强的AlphaGo使用了64个搜索线程,1920个CPU的集群和280个GPU的集群(其实也就二十多台机器)
三、AI战胜围棋大师李世石:我看悬
之前我们讨论过分布式MCTS时说过,MCTS很难在多机上并行,所以AlphaGo还是在一台机器上实现的LockFree的多线程并行,只不过Rollout和神经网络计算是在CPU和GPU集群上进行的。Google的财力肯定不只二三十台机器,所以分布式MCTS的搜索才是最大的瓶颈。如果这个能突破,把机器堆到成百上千台应该还是能提高不少棋力的。
我个人估计在3月与李世石的对弈中这个架构可能还很难有突破,可以增强的是RLPolicy的自对弈学习,不过这个提升也有限(否则不会只训练一天就停止了,估计也收敛的差不多了)。
所以,这一次,AI的胜算并没有李世石的大。
敬请持续关注小马资讯进行IT界行情分析!




2016年3月9日 下午8:17 沙发
AlphaGo 赢了。。。